Current Trends of Big Data Research Using the Korean National Health Information Database
Article information

Abstract
Recently, medical research using big data has become very popular, and its value has become increasingly recognized. The Korean National Health Information Database (NHID) is representative of big data that combines information obtained from the National Health Insurance Service collected for claims and reimbursement of health care services and results obtained from general health examinations provided to all Korean adults. This database has several strengths and limitations. Given the large size, various laboratory data, and questionnaires obtained from medical check-ups, their longitudinal nature, and long-term accumulation of data since 2002, carefully designed studies may provide valuable information that is difficult to obtain from other forms of research. However, consideration of possible bias and careful interpretation when defining causal relationships is also important because the data were not collected for research purposes. After the NHID became publicly available, research and publications based on this database have increased explosively, especially in the field of diabetes and metabolism. This article reviews the history, structure, and characteristics of the Korean NHID. Recent trends in big data research using this database, commonly used operational diagnosis, and representative studies have been introduced. We expect further progress and expansion of big data research using the Korean NHID.
INTRODUCTION
In recent years, big data analysis has become one of the mainstream areas of medical research. Since studies using big data have both strengths and limitations, they provide important insights that cannot be achieved by other forms of research. However, some possibilities of bias and caution in interpretation need to be acknowledged. The Korean National Health Information Database (NHID), which contains a nationwide claims database and health examination data, represents the Korean population and has become an attractive source of research in various fields. In this review, we describe the characteristics of the Korean NHID and provide an overview of recent trends in research related to diabetes.
HISTORY OF NATIONAL HEALTH INSURANCE SERVICE AND HEALTH EXAMINATION
The Medical Insurance Act was enacted in 1963 in Korea. At that time, the medical insurance society could be established voluntarily at an industrial establishment with 300 workers or more. Through several amendments, medical security for the entire population was achieved in 1989. The National Health Insurance Act, which was enacted in 1999 and enforced in January 2000, integrated all insurers into a single insurer (National Health Insurance Corporation [NHIC]) and established an independent organization for health care review and evaluation (Health Insurance Review Agency—currently the Health Insurance Review & Assessment Service [HIRA]) [1].
The implementation of health examinations for public officials, faculty and staff of private schools, and policyholders within the medical insurance corporation began in 1980. In the 1990s, screening for specific types of cancer was implemented and expanded to include public officials, faculty and staff of private schools, workplace policyholders, regional policyholders, and their dependents. Through legislation and promulgation of the Framework Act on Health Screening in 2008, the target diseases for general health screening were established, and the list of items included in the screening test was improved in 2009. General health screening for regional household members and dependents was expanded to include people aged 20 years or older in 2019 [2].
The NHID refers to big data combining information obtained from the National Health Insurance Service (NHIS) and health examinations. It includes qualification, insurance rate, medical check-up results, treatment details, elderly long-term nursing insurance data, clinic status, registered information on cancer and rare diseases, etc. This database was established in 2011, and a sample cohort database was established in 2012 [3].
OPERATIONAL STRUCTURE OF THE NATIONAL HEALTH INSURANCE SYSTEM
The NHIS and HIRA are under the supervision of the Ministry of Health and Welfare, which plays a role in the formulation and implementation of policies. The NHIS is a non-profit organization and a single insurer that manages the system in Korea. They are responsible for (1) managing the qualifications of insured individuals and their dependents; (2) imposing and collecting contributions; (3) paying healthcare service costs to healthcare service providers; and (4) purchasing health screening. Health service providers claim reimbursement of corporations’ share of healthcare service costs to the NHIS and HIRA and receive co-payment from insured individuals. The HIRA evaluates the adequacy of healthcare service costs by reviewing medical billing and claims and announces the review results to the NHIS and healthcare service providers (Fig. 1). The contribution of an employee to the NHIS is determined based on wages, and that of a self-employed person is calculated from age, gender, household income, property, and owned vehicles. National Health Insurance, Medical Aid, and Long-term Care Insurance are the main health care programs that universally cover the Korean population. Approximately 97% of the population is enrolled in the National Health Insurance program, and 3% of the population is covered by medical aid programs [1,4,5].
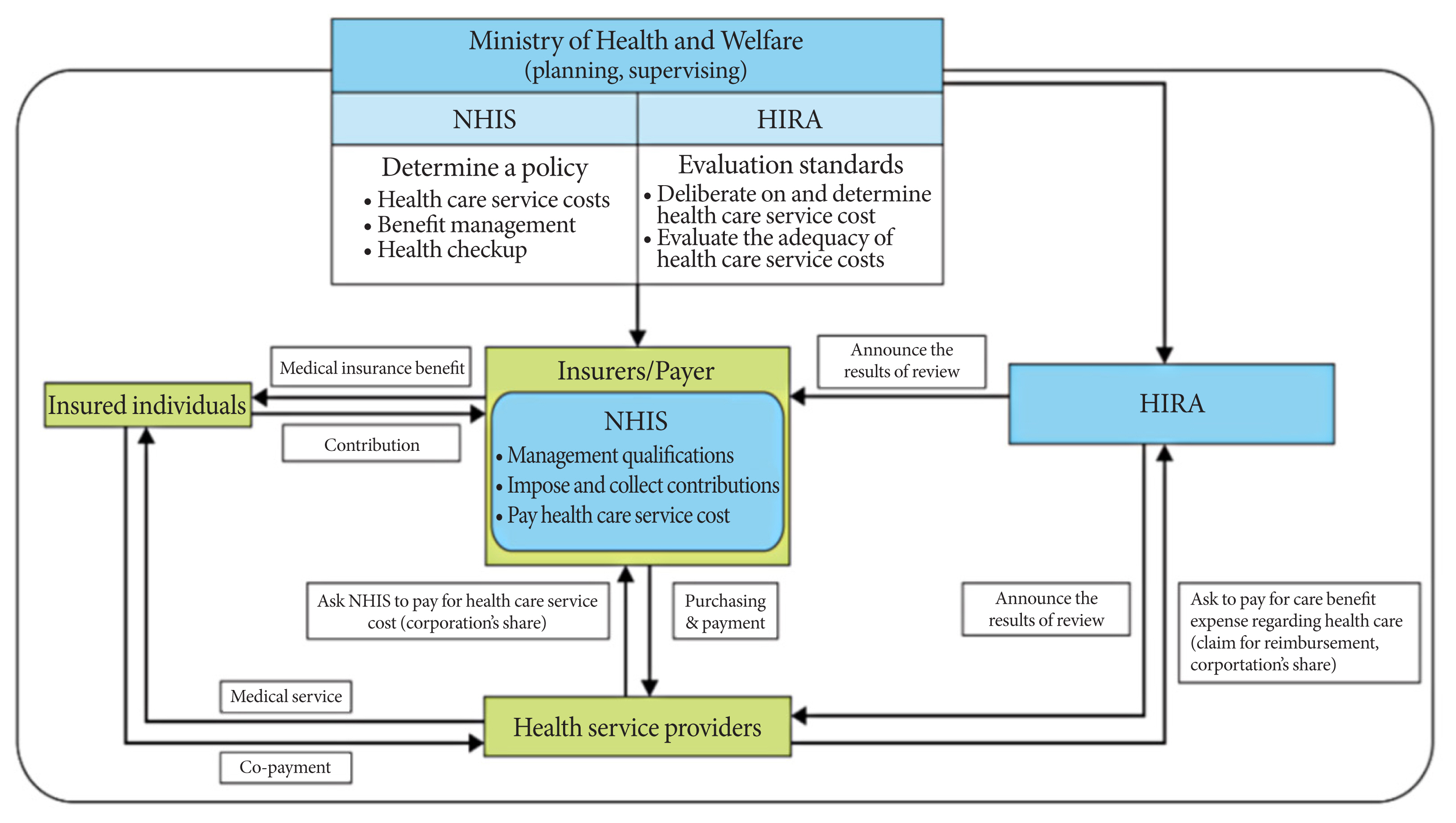
HEALTH SCREENING POLICY
Health screening is performed to improve the health of citizens and reduce health care costs through the prevention of cardiovascular and cerebrovascular diseases and early detection of major cancers. Heads and members of regional policyholders aged 20 years or older are recommended to undergo health screening once every 2 years. All employees engaged in office work and employee dependents are also recommended to undergo health screening once every 2 years. Employment-based policyholders engaged in non-office work must undergo health screening annually [2]. Cancer screening includes tests for stomach, liver, colorectal, breast, cervical, and lung cancers. The starting age of screening and test intervals is different for different types of cancers. All fees for general health screenings were charged to the NHIC. For cancer screening, 90% was charged to the NHIC, and 10% was co-paid by the examinee. However, all fees for medical aid beneficiaries are charged to national or local governments [2]. The number of participants who underwent health screening in the last 10 years is shown in Table 1. The number of eligible individuals and actual examinees has increased gradually, and approximately 15 million people participate in health examinations every year. The rate of general health screening was approximately 75% in the last 10 years but 67.8% in 2020 [6], possibly due to the coronavirus disease 2019 (COVID-19) pandemic.
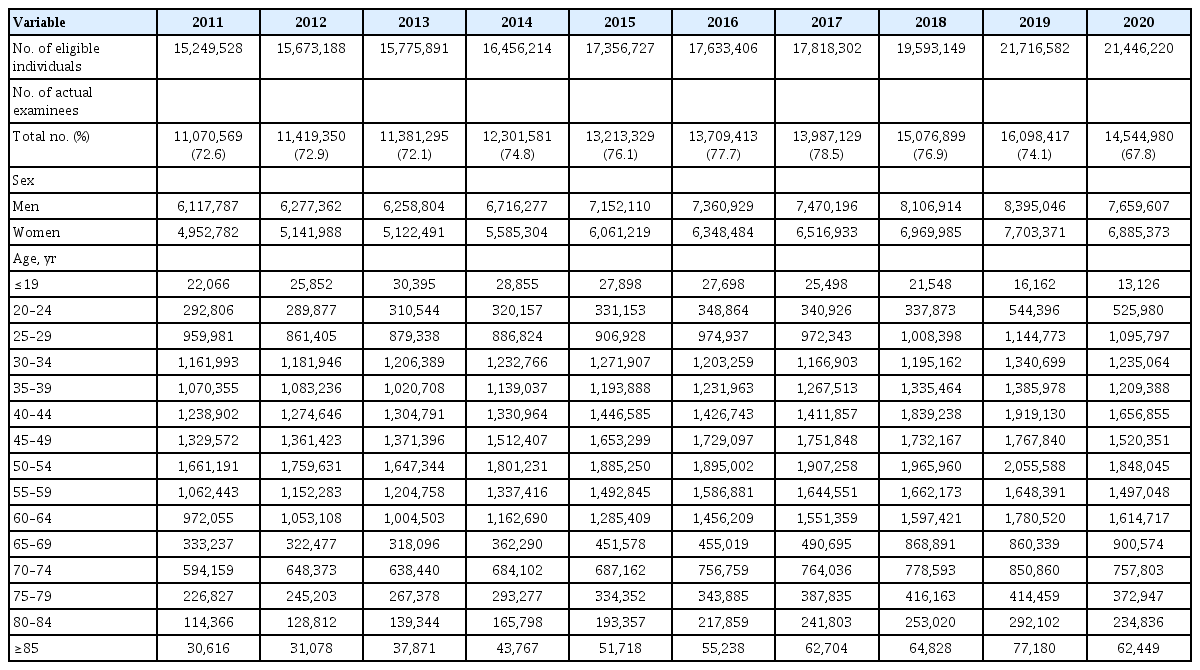
Number of eligible individuals and actual examinees of health examination in recent 10 years
TYPES AND VARIABLES COMPRISING NHID
There are two types of research databases. A customized database refers to health information data collected, managed, and maintained by the NHIC to be modified as requested for policy and academic research. The sample research database refers to the data standardized by extracting the sample to improve the limited access and use by investigators owing to the large size and personal, identifiable information issues. The sample cohort, medical check-up, elderly cohort, working women cohort, and infant medical check-up databases are available as sample research databases and allow long-term observation of the same individuals as a cohort [3]. The most recent sample cohort database includes one million people sampled based on data from 2006, which is approximately 2% of the total population (48,222,537). Stratified random sampling was used from 2,142 (2×17×21×3) strata constructed by sex (male and female: two groups), age (5-year age groups between 1 and 79 and 80 years and above: 17 groups), eligibility and contribution (deciles of regional policyholders, deciles of employment-based policyholders, and medical aid beneficiaries: 21 groups), and region (big city, middle or small cities, and rural areas: three groups) [7].
The NHID includes qualification, treatment, medical check-up, and clinic tables. Variables included in the qualification table are age, sex, location, type of subscription, and socioeconomic statuses, such as income rank, disability, and death. The cause of death was determined upon request in the sample cohort database. The treatment table is composed of a database including statements (T20), details of treatment (T30), type of disease (T40), and details of prescription (T60) on the data from medical institutions, dental, oriental, and pharmacy [7,8]. The details of the variables included in each table of the sample cohort database are presented in Table 2.
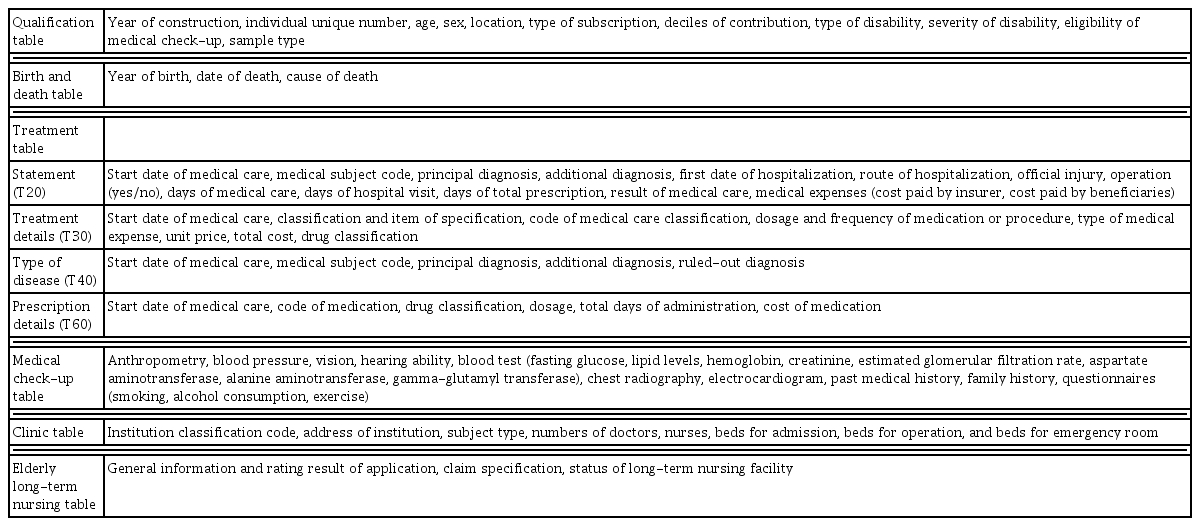
Variables included in the Korean National Health Information sample cohort database
The variables included in the health examination and questionnaire were changed over time (Table 3). Fifty-one variables were included in 2002–2008, 57 variables in 2009–2017, and 108 variables in 2018–2019. Currently, the parameters measured using blood tests include fasting blood glucose (FBG), total cholesterol, triglyceride, high-density lipoprotein cholesterol (HDL-C), low-density lipoprotein cholesterol (LDL-C), hemoglobin, creatinine, aspartate aminotransferase, alanine aminotransferase, and gamma-glutamyl transferase. The increase in the number of variables in 2018 to 2019 was mainly due to the detailed questionnaire on smoking and alcohol consumption habits [7].
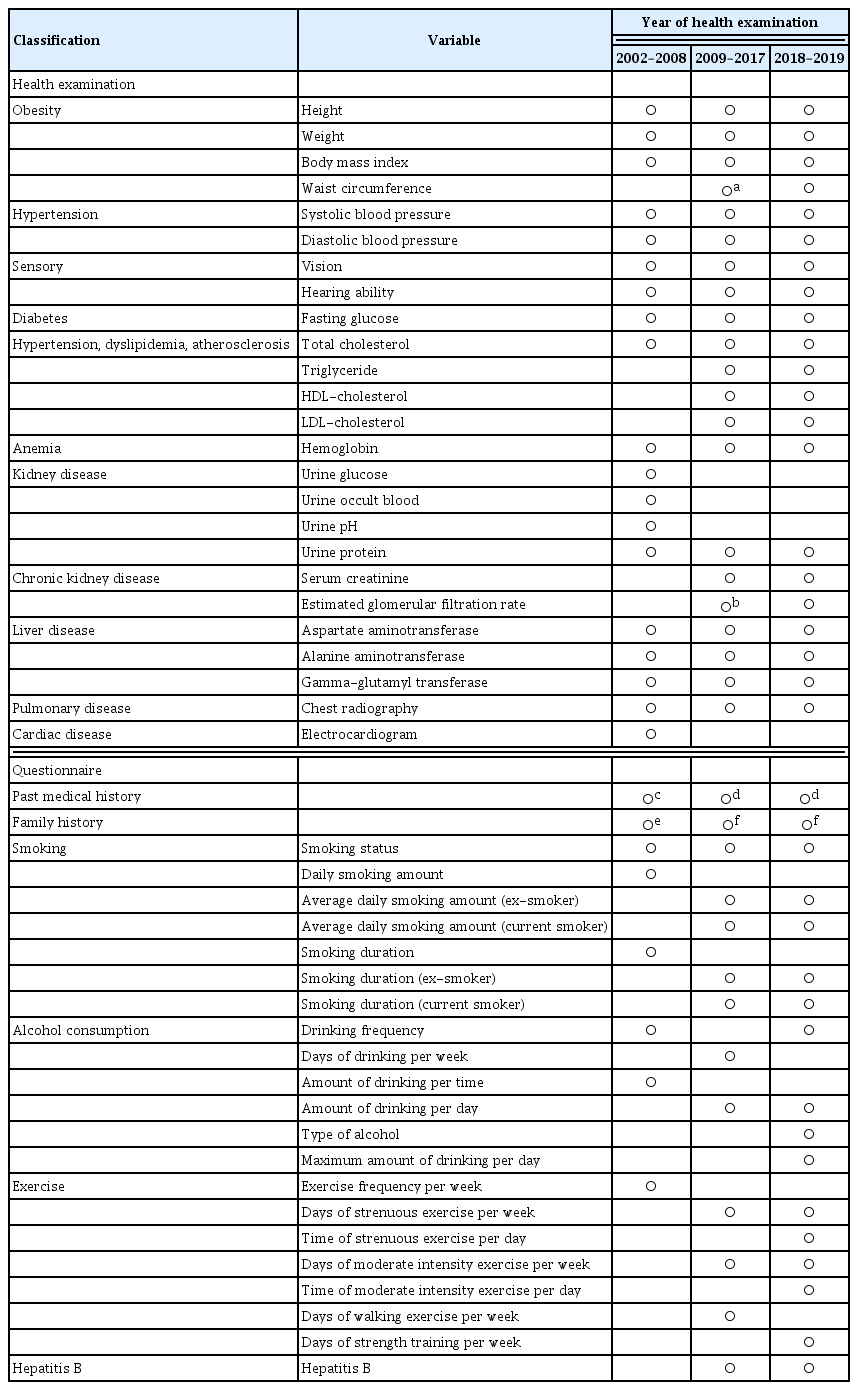
Variables and questionnaires included in the health examination database
STRENGTHS AND LIMITATIONS OF THE NHID
There are several strengths and limitations that should be carefully considered when using the NHID. The most powerful strength is the number of individuals included in the database. Since the NHIC is a single insurer that manages the National Health Insurance System in Korea, virtually all Koreans (approximately 50 million) are enrolled in this program; therefore, the NHID could represent the entire Korean population. Furthermore, the health screening policy described above enables the accumulation of medical check-up data, including anthropometric measurements, past medical history, family history, laboratory data, and detailed questionnaires on lifestyle factors. Combining the claims database with health examination data makes the Korean NHID unique. Mortality data from Statistics Korea or other databases can be linked using resident registration numbers for wider application of the database [9]. Given the large size of the database, it can be utilized to study rare diseases or rare complications of treatment and to study specific populations such as the elderly group [10]. One example is an observational study on acromegaly and cardiovascular outcomes, which included 1,874 patients with acromegaly [11]. It is also appropriate for long-term follow-up owing to the longitudinal nature of the database.
Since the data were not collected for research purposes, it is difficult to define causal relationships when performing outcome studies. The main purpose of establishing this database was to record claims and reimbursements; therefore, data on medications or procedures not covered by the NHIS are not available. Also, information on the severity of medical conditions are lacking and it is hard to reflect the health behaviors of beneficiaries. In addition, discrepancies may exist between the diagnosis encoded to claim medical bills and the actual disease. Therefore, setting an appropriate operational definition and validation may be crucial. As shown in Table 1, not all eligible individuals undergo health check-ups, which may impose a possibility of selection bias. Importantly, the linkage between the NHID and the electronic medical records of each hospital is very limited due to legal and privacy issues. Solving this problem might lead to a new leap forward in research using the NHID [12].
To request data from the National Health Insurance Sharing Service (http://nhiss.nhis.or.kr), researchers must obtain approval of the study protocol from the institutional review board and the data provision review committee at the NHIC. Access to and analysis of the NHID can be performed only in designated places, and the raw data cannot be retrieved from the server. Only the analyzed data can be obtained after approval. However, remote access and analysis are available for sample research databases. Recently, the process of requesting and reviewing data applications has taken a long time owing to the great increase in the number of researchers interested in the NHID.
TRENDS OF RESEARCH USING NHID
Since the establishment of the NHID, research and publications based on this database have increased significantly (Fig. 2). We searched PubMed using the keyword ‘NHIS’ or ‘National Health Insurance System’ or ‘NHID’ and ‘Korea’ or ‘Korean.’ A total of 1,692 published articles were identified. Among these, 595 articles (35.2%) were on diabetes, metabolism, metabolic syndrome (MetS), obesity, lipids, and cholesterol. A total of 397 articles were identified using the keyword ‘diabetes.’
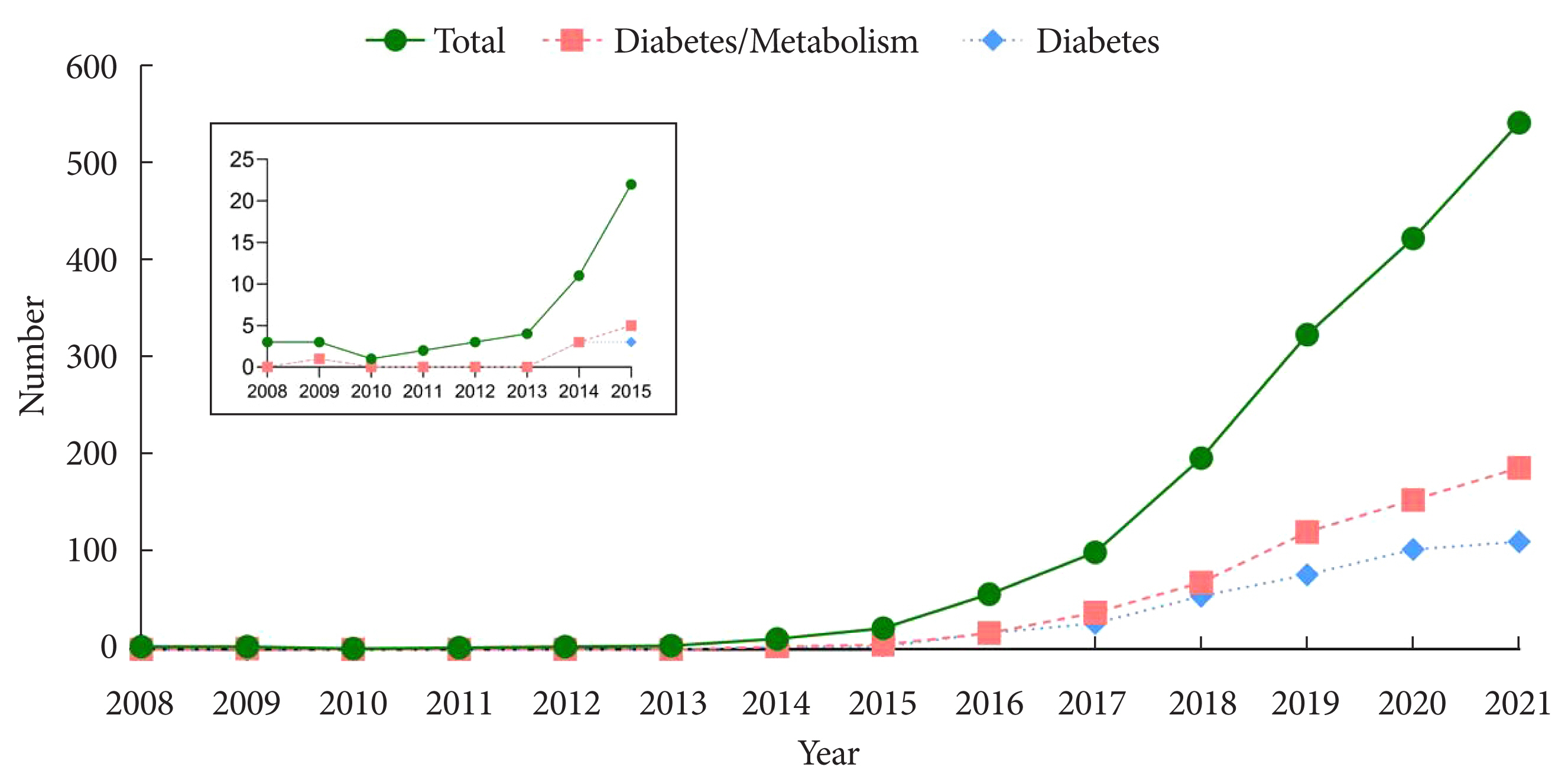
The number of publications using National Health Information database from 2008 to 2021.
THE OPERATIONAL DEFINITION OF OUTCOMES IN DIABETES AND METABOLISM RESEARCH
Type 2 diabetes mellitus
In research using the NHID, the operational definition of diabetes was applied considering the characteristics of the database. The proportion of patients with diabetes was 13.2% according to the International Classification of Disease, 10th revision (ICD-10) codes (E11–14) alone, and 8.7% based on prescription data alone in 2013 [13]. The Taskforce Team of Diabetes Fact Sheet of the Korean Diabetes Association concluded the operational definition of diabetes as either (1) patients who had both recordings of diagnosis (ICD-10 codes E11–14 for diabetes as either principal diagnosis or 1st to 4th additional diagnosis at least once a year) and prescription of anti-diabetic drugs; or (2) patients whose FBG levels from health check-up data were ≥126 mg/dL (Table 4) [13]. According to this definition, the prevalence of diabetes was 11.4% in 2013.

The operational definitions of commonly used outcomes and covariates in the field of diabetes and metabolism research
Dyslipidemia
The presence of dyslipidemia was defined as the presence of at least one claim per year under ICD-10 code E78 and at least one claim per year for the prescription of lipid-lowering agents or total cholesterol ≥240 mg/dL (Table 4) [14–16]. Lipid-lowering drugs include statins, ezetimibe, and fibrates. In addition to this operational definition, dyslipidemia was defined using health check-up data and prescriptions of lipid-lowering drugs. Hypercholesterolemia was defined as a total cholesterol level ≥240 mg/dL or the use of a lipid-lowering drug. Hyper-LDL cholesterolemia was defined as a serum LDL-C level ≥160 mg/dL or the use of a lipid-lowering drug. Hypo-HDL cholesterolemia was defined as a serum HDL-C level <40 mg/dL. Hypertriglyceridemia was defined as a serum triglyceride ≥200 mg/dL. In the Korea Dyslipidemia Fact Sheet 2020, dyslipidemia was defined as satisfying one of the definitions for LDL-C, HDL-C, or triglyceride as stated above [17].
Hypertension
The presence of hypertension was defined as the presence of at least one claim per year under ICD-10 codes I10 or I11 and at least one claim per year for the prescription of antihypertensive agents or systolic blood pressure (BP) ≥140 mm Hg or diastolic BP ≥90 mm Hg (Table 4) [18,19]. Other studies have used a different operational definition of hypertension: ICD-10 codes I10–I13 or I15 for the hypertensive disease usually recorded twice in the outpatient clinic, or once during hospitalization, and a history of prescription of antihypertensive drugs [20,21]. This definition includes hypertensive end-organ damage, such as hypertensive renal disease (I12), hypertensive heart and renal disease (I13), and secondary hypertension (I15). In the Korea Hypertension Fact Sheet 2020, hypertension is defined as at least one health insurance claim for the diagnosis of essential hypertension (I10) each year [22].
Myocardial infarction and stroke
Myocardial infarction (MI) was defined according to ICD-10 codes I21 or I22 recorded during hospitalization [23,24]. Stroke was defined using principal diagnosis codes from I60 to I64 with the enforcement of brain computerized tomography or magnetic resonance imaging at the emergency center or outpatient clinic, or during hospitalization [25]. Ischemic stroke was defined as a recording of ICD-10 codes I63 or I64 during hospitalization with a claim for brain magnetic resonance imaging or brain computerized tomography (Table 4) [23,24]. This definition has been widely adopted in previous studies using claims databases [26,27]. According to the validation of diagnostic codes of clinical outcomes in the NHID, the primary discharge diagnostic codes for MI (ICD-10 codes I21 and I22) showed favorable reliability, with a positive predictive value (PPV) of 92% [28]. In stroke and intracranial hemorrhage (ICH), in addition to the primary discharge diagnostic codes, consideration of relevant clinical information, such as hospitalization duration, imaging studies, and prescription of antithrombotic agents, could improve the accuracy of diagnosis. For ischemic stroke (ICD-10 codes I63 and I64) and ICH (ICD-10 I60–62), the combination of primary diagnostic codes during hospitalization and brain imaging studies showed a PPV and sensitivity of 92.2% and 91.2%, respectively [28]. For ICH, the combination of primary diagnostic codes with hospitalization and brain imaging studies showed a PPV and sensitivity of 81.4% and 95.1%, respectively [28].
Heart failure
Heart failure was defined using ICD-10 code I50 with more than one diagnosis during hospitalization or in an outpatient clinic (Table 4) [29]. Another study defined heart failure as ICD-10 I50 during hospitalization [30].
Chronic kidney disease and end-stage renal disease
Chronic kidney disease (CKD) was defined using the ICD-10 codes N18 or N19 and an estimated glomerular filtration rate of <60 mL/min/1.73 m2 was calculated using the CKD Epidemiology Collaboration Equation on more than two occasions during the medical check-up [31,32]. End-stage renal disease was defined using a combination of ICD-10 codes (N18–N19, Z49, Z94.0, Z99.2) and initiation of renal replacement therapy for 30-days or more, and/or kidney transplantation during hospitalization (Table 4) [33].
REPRESENTATIVE STUDIES RELATED TO DIABETES AND METABOLISM USING THE KOREAN NHID
Diabetes Fact Sheet in Korea 2021
The representative national estimates of diabetes in Korea can be analyzed using the Korea National Health and Nutrition Examination Survey (KNHANES) and the Korea NHID [34]. Among Korean adults aged ≥30 years, the estimated prevalence of diabetes was 16.7% in 2020. The proportion of adults with diabetes who achieved a glycosylated hemoglobin target of <6.5% was 24.5%. The prescription patterns of anti-diabetic drugs were analyzed. It was reported that 86.0% of adults with previously diagnosed diabetes were taking oral glucose-lowering medications without insulin, and 7.5% were treated with insulin. Sulfonylurea was the most commonly used drug, followed by metformin in 2002. During the past decade, the use of metformin has increased steadily to 86% of total antidiabetic drug prescriptions and metformin was the most frequently prescribed antidiabetic agent in Korea in 2018. The use of dipeptidyl peptidase-4 (DPP-4) inhibitors increased markedly after their release in 2008 and dramatically increased to 62.0% in 2018. There was a steady decrease in the use of sulfonylureas/glinides, from 84% in 2002 to 43% in 2018. The use of insulin and thiazolidinediones remained stable from 2002 to 2018 [34].
Gestational diabetes mellitus in Koreans
The clinical characteristics of gestational diabetes mellitus (GDM) in Korea have been reported using a large-scale population dataset from the NHID [35]. The prevalence of GDM in Korean women between 2011 and 2015 was 12.7 %. The operational definition of GDM was as follows: visited the outpatient clinic more than twice with GDM codes and no previous history of diabetes; did not have a claim for diabetes based on ICD-10 codes E10–14 or oral antidiabetic drug or insulin before pregnancy; did not have an FBG level ≥126 mg/dL before pregnancy. The incidence rate of GDM increases with advancing age, pre-pregnancy body mass index, waist circumference, and FBG level [35].
Cholesterol and BP levels and development of cardiovascular disease in Koreans with type 2 diabetes mellitus
In recent guidelines, cholesterol targets are based on several primary- and secondary-prevention statin trials that have shown improved outcomes with more intensive LDL-C lowering. In addition to randomized controlled trials (RCTs), the optimal lipid or BP levels to prevent cardiovascular disease (CVD) could be investigated through big data analysis. Patients with type 2 diabetes mellitus over 40 years of age without CVD were divided into statin users and non-users, and the relationship between LDL-C levels and the risk of CVD was analyzed [36]. There was an increased risk of CVD in individuals with an LDL-C level ≥130 mg/dL among those with type 2 diabetes mellitus who did not take statins. The risk of CVD was significantly higher in those taking statins with an LDL-C level of ≥70 mg/dL. The researchers recommended statin therapy for the primary prevention of CVD, with a target LDL-C level of <70 mg/dL [36].
The relationship between BP and CVD risk in patients with type 2 diabetes mellitus without CVD was analyzed. Systolic BP 130 to 139 mm Hg was associated with a significant increase in the incidence of stroke (hazard ratio [HR], 1.15; 95% confidence interval [CI], 1.12 to 1.18) and MI (HR, 1.05; 95% CI, 1.02 to 1.09) compared to systolic BP 110 to 119 mm Hg [18]. Subjects with a diastolic BP of 80 to 84 mm Hg had a higher risk of CVD than those with a diastolic BP of 75 to 79 mm Hg. The overall relationship between BP and CVD risk was positive, with greater strength observed in the younger age groups. The optimal cutoff for Korean patients with type 2 diabetes mellitus associated with a lower CVD risk may be 130 mm Hg for systolic BP or 80 mm Hg for diastolic BP [18]. Another study examined the association of BP categories before age of 40 years with the risk of CVD later in life. In both young men and women, stage 1 hypertension (systolic BP 130 to 139 mm Hg; diastolic BP 80 to 89 mm Hg) and stage 2 hypertension (systolic BP ≥140 mm Hg; diastolic BP ≥90 mm Hg) were associated with increased risk of CVD, coronary heart disease, and stroke [37].
Risk of cardiovascular events and death associated with the initiation of sodium-glucose co-transporter-2 inhibitors compared with DPP-4 inhibitors: CVD-REAL 2 multinational cohort study
This study utilized data sourced from de-identified health records in 13 different countries located in four geographical regions, which could be linked to CVD outcomes and mortality data [38]. Information from the Korean NHID was used. All initial episodes of new initiation of either sodium-glucose co-transporter-2 (SGLT2) inhibitors or DPP-4 inhibitors were selected. The use of a new SGLT2 inhibitor was associated with a substantially lower risk of hospitalization for heart failure (HR, 0.69; 95% CI, 0.61 to 0.77) and death (HR, 0.59; 95% CI, 0.52 to 0.67). The risks of MI and stroke were also significantly lower with SGLT2 inhibitors than with DPP-4 inhibitors [38]. A large number of patients, the consistency of the findings across 13 countries with different healthcare systems, the inclusion of different SGLT2 inhibitors and DPP-4 inhibitors, and the exclusion of anyone who had been on a DPP-4 inhibitor or SGLT2 inhibitor for at least a year before follow-up started all contribute to the robustness and credibility of these findings [39]. In contrast to clinical trials conducted in highly selected populations, real-world evidence (RWE) can be generalized to so-called average patients with type 2 diabetes mellitus.
Use of fenofibrate on cardiovascular outcomes in statin users with MetS
Recently, RWE analysis has been conducted using a large-scale population-based cohort. The value of RWE begins with the limitations of RCTs. RCTs provide the highest level of evidence in medical science but the inevitable limitations of RCTs include limited patient populations and the trial environment, which is difficult to reproduce in the real world [5,40]. The potential role of fenofibrate in cardiovascular risk reduction was analyzed using the Korean NHID [41]. Early clinical trials on fibrates are promising, but their role in CVD risk management has gradually diminished in the statin era. Using the Korean National Health Insurance Service-Health Screening Cohort, researchers attempted to demonstrate the additional benefits of fenofibrate add-on to statins [41]. Patients with MetS were included in the study. Propensity score matching was performed for those treated with fenofibrate plus statins and those treated with statins only. The risk of composite CVD, including coronary heart disease, ischemic stroke, and cardiovascular mortality, was significantly reduced in the combined treatment group compared with the statin-only group (adjusted HR, 0.74; 95% CI, 0.58 to 0.93; P=0.01). In particular, the HRs of composite CVD were lower in those with high triglyceride or low HDL-C (adjusted HR, 0.64; 95% CI, 0.47 to 0.87; P=0.005) compared with those with low triglyceride and high HDL-C. This study may influence treatment guidelines for the benefit of fenofibrate in improving residual cardiovascular risk in patients with dyslipidemia during statin use.
Altered risk for cardiovascular events with changes in the MetS status
The KNHANES data, a nationally representative sample of Korea, is limited in that longitudinal follow-up data for the same subjects cannot be obtained. In contrast, the NHID contains serial data of the same individuals who undergo regular health examinations. In this regard, noteworthy studies have utilized serial data from the Korea NHID to examine the cumulative effect, variability, or changes in metabolic parameters [14–16,19,23,26,33]. An example is a study that showed an altered risk of cardiovascular events with changes in the MetS status [42]. Among those who had undergone three or more health examinations, 72.7%, 15.6%, 6.1%, and 5.6% were in the MetS-free, MetS-chronic, MetS-developed, and MetS-recovery groups, respectively. At a median follow-up of 3.5 years, the MetS-recovery group had a significantly lower major adverse cardiovascular event (MACE) risk than the MetS-chronic group (adjusted incidence rate ratio [IRR], 0.85; 95% CI, 0.83 to 0.87). The MetS-developed group had a significantly higher MACE risk than the MetS-free group (adjusted IRRs, 1.36; 95% CI, 1.33 to 1.39). Among the MetS criteria, the development of the elevated BP criterion was related to the largest increase in MACE. Healthcare providers may consider these results when planning a public health strategy to alleviate the burden of MACE.
CONCLUSIONS
In this review, we have summarized the history, structure, and characteristics of the Korean NHID. Recent trends in big data research using this database and representative studies have been introduced. Due to the purpose and nature of this database, some limitations exist. However, several strengths also highlight the value of this database. A careful study design and analysis of real-world big data may produce valuable information that can complement other forms of research. In the future, institutional support for the linkage between the NHID and other forms of databases would be crucial for the expansion of usability.
Notes
CONFLICTS OF INTEREST
Seung-Hwan Lee has been associate editors of the Diabetes & Metabolism Journal since 2022. He was not involved in the review process of this review. Otherwise, there was no conflict of interest.
FUNDING
This research was supported by a grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health and Welfare, Republic of Korea (Grant Number: HI18-C0275).
ACKNOWLEDGMENTS
None