- Current
- Browse
- Collections
-
For contributors
- For Authors
- Instructions to authors
- Article processing charge
- e-submission
- For Reviewers
- Instructions for reviewers
- How to become a reviewer
- Best reviewers
- For Readers
- Readership
- Subscription
- Permission guidelines
- About
- Editorial policy
Articles
- Page Path
- HOME > Diabetes Metab J > Volume 34(4); 2010 > Article
-
Original ArticlePolymorphisms of the
Reg 1α Gene and Early Onset Type 2 Diabetes in the Korean Population - Bo Kyung Koo1,2, Young Min Cho1,2, Kuchan Kimm3, Jong-Young Lee3, Bermseok Oh3, Byung Lae Park4, Hyun Sub Cheong4, Hyoung Doo Shin4,5, Kyung Soo Ko6, Sang Gyu Park7, Hong Kyu Lee1,2, Kyong Soo Park1,2
-
Korean Diabetes Journal 2010;34(4):229-236.
DOI: https://doi.org/10.4093/kdj.2010.34.4.229
Published online: August 31, 2010
- 3,463 Views
- 23 Download
- 1 Crossref
1Department of Internal Medicine, Seoul National University College of Medicine, Seoul, Korea.
2Genome Research Center for Diabetes and Endocrine Disease, Clinical Research Institute, Seoul National University Hospital, Seoul, Korea.
3National Institute of Health, Seoul, Korea.
4Department of Genetic Epidemiology, SNP Genetics, Inc., Seoul, Korea.
5Department of life science, Sogang University, Seoul, Korea.
6Department of Internal Medicine, Inje University College of Medicine, Busan, Korea.
7Clinical Research Institute, Seoul National University Hospital, Seoul, Korea.
- Corresponding author: Kyong Soo Park. Department of Internal Medicine, Seoul National University College of Medicine, 101 Daehang-no, Jongno-gu, Seoul 110-744, Korea. kspark@snu.ac.kr
Copyright © 2010 Korean Diabetes Association
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
ABSTRACT
-
Background
- The Reg gene has been reported to be expressed in regenerating islets and Reg1 protein to be up-regulated at an early stage of diabetes in mice. As human Reg1α is homologous with murine Reg1, we investigated whether common variants in Reg1α are associated with type 2 diabetes in the Korean population.
-
Methods
- We sequenced the Reg1α gene to identify common polymorphisms using 24 Korean DNA samples. Of 11 polymorphisms found, five common ones (g.-385T>C [rs10165462], g.-36T>G [rs25689789], g.209G>T [rs2070707], g.1385C>G [novel], and g.2199G>A [novel]) were genotyped in 752 type 2 diabetic patients and 642 non-diabetic subjects.
-
Results
- No polymorphism was associated with the risk of type 2 diabetes. However, g.-385C and g.2199A lowered the risk of early-onset type 2 diabetes, defined as a diagnosis in subjects whose age at diagnosis was 25 years or more but less than 40 years (odds ratio [OR], 0.721 [0.535 to 0.971] and 0.731 [0.546 to 0.977] for g.-385C and g.2199A, respectively) and g.1385G increased the risk of early-onset diabetes (OR, 1.398 [1.055 to 1.854]). Although adjusting for errors in multiple hypotheses-testing showed no statistically significant association between the three individual polymorphisms and early-onset diabetes, the haplotype H1, composed of g.-385C, g.1385C, and g.2199A, was associated with a reduced risk of early-onset diabetes (OR, 0.590 [0.396 to 0.877], P = 0.009).
-
Conclusion
- Polymorphisms in the Reg1α were not found to be associated with overall susceptibility to type 2 diabetes, though some showed modest associations with early-onset type 2 diabetes in the Korean population.
- The Reg gene was discovered during the screening of a regenerating islet-derived cDNA library in mice [1]. In the rodent model, the Reg1 gene encodes a protein expressed in the pancreatic exocrine tissue and in regenerating islet [1,2]. Reg1 protein increased DNA synthesis in pancreatic beta cells [2,3] and ameliorated experimental diabetes in rats [2,4]. Non-obese diabetes (NOD) mice expressing Reg1 in beta cells showed a delay in the onset of diabetes, whereas islets from Reg knockout mice showed a lower proliferative capacity [5], suggesting a possible role for this protein in replication, growth, and maturation of islet beta cells. A recent study showed that depletion of Reg1 was associated with the pathogenesis of impaired glucose tolerance of pancreatitis-associated diabetes [6] and furthermore, administration of Reg1 protein improved the insulin secretion capacity in a diabetic rat model [4,6], implying that Reg1α might play a role in the pathogenesis of type 2 diabetes.
- In humans, four members of the Reg family have been discovered: Reg1α, Reg1β, HIP/PAP, and the homologue of islet neogenesis-associated protein (IN-GAP) [7,8]. Of these, Reg1α is encoded by a gene located on chromosome 2p12, which is homologous to the mouse Reg1 gene [1]. Expression of the Reg1α gene has been found in pancreatic ductal cells, exocrine cells, and islet cells in human and is increased in type 2 diabetes compared to normal subjects [9], suggesting that Reg1α might play a role in the pathogenesis of type 2 diabetes in humans. However, the clinical implications of genetic variants of Reg1α are largely unknown. Only one previous study screened for the Reg1α gene by PCR-SSCP. This study used a very small number of subjects in Thailand and showed no association between a polymorphism in exon 1 and type 2 diabetes mellitus [10]. To more thoroughly investigate the possible association of Reg1α with type 2 diabetes, we searched for common variants in Reg1α among Korean populations, and investigated whether common variants in Reg1α are associated with type 2 diabetes in this population.
INTRODUCTION
- Subjects
- We studied 752 unrelated patients with type 2 diabetes from the Diabetes Clinic of Seoul National University Hospital (age, 59 ± 10 years; 349 men, 403 women) and 642 non-diabetic control subjects (age, 65 ± 4 years; 288 men, 354 women). All subjects in this study were of Korean ethnicity. Type 2 diabetes was diagnosed according to World Health Organization criteria [11] and subjects with positive GAD antibodies or with the mitochondrial DNA 3243 mutation were excluded. Patients with type 2 diabetes were divided with into three subgroups according to age at diagnosis, according to previous epidemiologic studies [12-14]: 1) early-onset diabetes (n = 119, subjects whose age at diagnosis was 25 years or more but less than 40 years; 70 men, 49 women); 2) average-onset diabetes (n = 496, subjects whose age at diagnosis was 40 years or more but less than 60 years; 223 men, 273 women); and 3) late-onset diabetes (n = 137, subjects whose age at diagnosis was 60 years or more; 56 men, 49 women). Genotype frequencies were compared among the non-diabetic, diabetic, early-onset diabetic, average-onset diabetic, and late-onset diabetic groups. Selection of the non-diabetic control subjects was made according to the following criteria: 60 years old or older, no past history of diabetes, no diabetes in first-degree relatives, a fasting plasma glucose concentration of less than 6.1 mmol/L, and an A1c level of less than 5.8%.
- The Institutional Review Board of the Clinical Research Institute at Seoul National University Hospital approved the study protocol and informed consent for genetic analysis was obtained from each subject.
- Each study subject was examined in the morning after an overnight fast. Height, weight, circumferences of waist and hip, and blood pressure were measured. Blood samples were drawn for biochemical measurements (fasting plasma glucose, fasting plasma insulin, A1c, total cholesterol, triglyceride, and high density lipoprotein cholesterol) and DNA extraction. The clinical characteristics of the study population are shown in Table 1. Compared with the non-diabetic control subjects, patients with type 2 diabetes were younger and had a higher mean body mass index (BMI), higher waist circumference, higher systolic blood pressure, and higher fasting plasma glucose and fasting triglyceride levels.
- Identification of polymorphisms of human Reg1α and genotyping
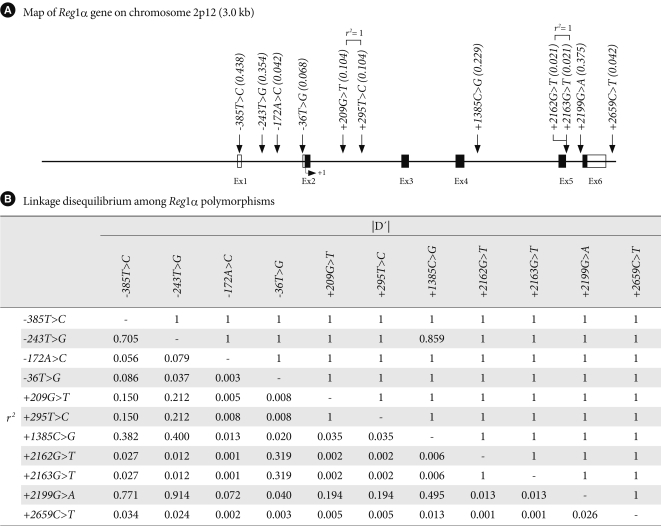
- Twenty-four DNA samples from Korean subjects for initial sequencing were randomly selected from unrelated local residents with no history of familial disease. We sequenced all exons and exon-intron boundaries including the promoter region (~1.5 kb) to discover polymorphisms in these 24 Korean DNA samples using an ABI PRISM 3730 DNA analyzer (Applied Biosystems, Foster City, CA, USA). Eight primer sets of Reg1α were designed for the amplification and sequencing analysis based on GenBank sequences (Ref. Genome seq. for REG1A; NT_022184). Sequence variants were verified by chromatograms.
- Genotyping polymorphic sites with fluorescence polarization detection was performed using TaqMan [15] as described in a previous study [16]. Genotyping quality control was performed in 10% of samples by duplicate checking (rate of concordance of duplicates was > 99%).
- Statistical analyses
- All data were analyzed using SPSS/Win programs (SPSS Inc., Chicago, IL, USA). Results are presented as means ± standard deviation. Variables not normally distributed were logarithmically transformed before statistical analysis. The χ2 test was used to determine whether individual polymorphisms were in Hardy-Weinberg equilibrium (P > 0.05). We examined a widely used measure of linkage disequilibrium (LD) between all pairs of biallelic loci, Lewontin's D' (|D'|) [17], and r2. Haplotypes and their frequencies were inferred using the algorithm developed by Stephens et al. [18]. Logistic regression analysis was used for calculating odds ratios (ORs), 95% confidence interval, and corresponding P values, after controlling for age, sex, and BMI as covariates. Genotypes were given codes of 0, 1, and 2 in the additive model; 0, 1, and 1 in the dominant model; or 0, 0, and 1 in the recessive model, respectively. In the additive model, the OR was expressed per difference in number of rare alleles. Multiple regressions were used for the association analyses of diabetes-related phenotypes. Only non-diabetic subjects were used for the association analyses of metabolic phenotypes, as treatment for type 2 diabetes can affect phenotypic values in diabetics. For adjusting errors in multiple hypotheses-testing, we used the false discovery rate (FDR) [19]. The FDR was applied to the sex- and BMI-adjusted multivariate models examining the additive effect of each gene polymorphism. Haplotype associations were also estimated using PHASE, which was used to construct a haplotype for each subject with the greatest probability, based on Bayesian statistics [18]. P values of <0.05 were considered statistically significant.
METHODS
- Identification of polymorphisms in the Reg1α gene
- From the DNA samples of 24 Koreans, 11 single nucleotide polymorphisms (SNPs) were identified in the Reg1α gene (Fig. 1). Five common variants (g.-385T>C [rs10165462], g.-36T>G [rs25689789], g.209G>T [rs2070707], g.1385C>G [novel], and g.2199G>A [novel)] were selected a for larger-scale genotyping based on location (SNPs in exon and promoter were preferred), LD (only one SNP if there are absolute LDs [γ2 > 0.9]) [20], frequency (> 0.05), and haplotype tagging status [21]. The genotype distributions of all loci in the Reg1α gene were in Hardy-Weinberg equilibrium (P > 0.05).
- Association with type 2 diabetes
- We assessed the associations between each genotype and type 2 diabetes by logistic regression analyses adjusting for age, sex, and BMI. No polymorphism was found to be associated with the risk of type 2 diabetes (Table 2). Next, we examined the association between the Reg1α gene polymorphisms and age at diagnosis of type 2 diabetes. g.1385G was more frequently found in cases of early-onset diabetes, defined as mentioned above, than in the control group (sex and BMI-adjusted OR, 1.398 [1.055 to 1.854]; P = 0.020 in the additive model) (Table 2). In contrast, g.-385C and g.2199A were associated with a decreased risk of early-onset type 2 diabetes with ORs of 0.721 (0.535 to 0.971) (P = 0.031) and 0.731 (0.546 to 0.977) (P = 0.035), respectively in the additive model. However, when the FDR was used to adjust for errors from multiple comparisons, these effects lost statistical significance (Table 2).
- Five common haplotypes (frequency > 0.05) were identified with the five polymorphisms genotyped in the Reg1α gene, which accounted for 96.7% of all observed haplotypes. No haplotype was found to be associated with type 2 diabetes in the additive or recessive models (Table 3). However, the haplotype H1 (C-T-G-C-A), consisting of g.-385C, g.1385C, and g.2199A, decreased the risk of early-onset diabetes (sex and BMI-adjusted OR, 0.590 [0.396 to 0.877]; P = 0.009) and the haplotype H2 (T-T-G-G-G), consisting of g.-385T, g.1385G, and g.2199G increased the risk of early-onset diabetes (sex and BMI-adjusted OR, 1.644 [1.091 to 2.538], P = 0.018) in the dominant model (Table 3).
- Association with diabetes-related phenotypes
- For the association analysis of the diabetes-related phenotypes, only non-diabetic subjects were used because, as mentioned above, treatment for diabetes can affect the measured parameters. We found that none of the metabolic phenotypes, including fasting plasma glucose, triglyceride, fasting plasma insulin, homeostasis model assessment of insulin resistance (HOMA-IR), and HOMA-beta cell function, were associated with any individual polymorphism (data not shown).
RESULTS
- In this study, we identified 11 SNPs in the Reg1α gene but found that no SNP was associated with susceptibility to type 2 diabetes mellitus. However, the g.-385T>C, g.1385C>G, and g.2199G>A SNPs seemed to be associated with early-onset diabetes; g.1385G increased the risk of early-onset diabetes and g.-385C and g.2199A decreased this risk. Although FDR showed no statistical significance for the associations between those polymorphisms and early-onset diabetes, the haplotype H1 composed of g.-385C, g.1385C, and g.2199A was found to be associated with a reduced risk of early-onset diabetes.
- Reg1 protein is thought to be a stimulator of beta cell proliferation and neogenesis [2,3]. The fact that Reg1 affects the proliferation of beta cells only in the early stage of diabetes and that Reg1 level is reduced during overt stage diabetes [22] suggest that Reg gene expression may be important during development of diabetes mellitus in the early stage. In support of this possibility, it has been shown in the NOD mouse model that overexpression of Reg1 in beta cells delayed the onset of diabetes [5].
- At this time, however, it is not clear how Reg1α g.-385T>C, g.1385C>G, and g.2199G>A affect the development of diabetes. Reg1α g.-385C is in a gene regulatory region and might be one of the E-box DNA elements (CANNTG: C with underline corresponds with g.-385C) and it is possible that this element could bind with basic helix-loop-helix (bHLH) transcription factors such as NeuroD and USF-1 [23]. Since there has been some debate as to whether Reg1α g.-385T>C is in the promoter area or not, we performed 5' rapid amplification of cDNA ends (RACE)-PCR [24] to confirm its location. We found that Reg1α g.-385 is located in the 5' untranslated region (data not shown). Recently, pancreas-derived cells exposed to Reg1 were reported to grow by activation of the signal transduction pathway involving the mitogen-activated protein kinase phophatases (MKP-1) and cyclins, with concomitant induction of MKP-1 [25]. The mechanisms of association between the identified SNPs in Reg1α and early-onset diabetes will need to be elucidated in independent studies.
- In conclusion, individual polymorphisms in the Reg1α gene were not statistically associated with an overall susceptibility to either type 2 diabetes or early-onset diabetes. Although the modest association identified between SNPs of Reg1α and early-onset diabetes in the haplotype association study must be interpreted with caution, the comprehensive search for SNPs by re-sequencing and the examination of the clinical implications of SNPs of Reg1α in a Korean population are novel. Further studies with a larger number of subjects in a more diverse population are needed to conclusively elucidate the association between genetic polymorphisms in Reg1α and diabetes.
DISCUSSION
-
Acknowledgements
- This work was supported by the intramural grant of the National Institute of Health, Korea and a grant from the Korea Health 21 R & D Project, Ministry of Health & Welfare, Republic of Korea (00-PJ3-PG6-GN07-001).
ACKNOWLEDGMENT
- 1. Terazono K, Yamamoto H, Takasawa S, Shiga K, Yonemura Y, Tochino Y, Okamoto H. A novel gene activated in regenerating islets. J Biol Chem 1988;263:2111-2114. ArticlePubMed
- 2. Okamoto H. The Reg gene family and Reg proteins: with special attention to the regeneration of pancreatic beta-cells. J Hepatobiliary Pancreat Surg 1999;6:254-262. PubMed
- 3. Levine JL, Patel KJ, Zheng Q, Shuldiner AR, Zenilman ME. A recombinant rat regenerating protein is mitogenic to pancreatic derived cells. J Surg Res 2000;89:60-65. ArticlePubMed
- 4. Watanabe T, Yonemura Y, Yonekura H, Suzuki Y, Miyashita H, Sugiyama K, Moriizumi S, Unno M, Tanaka O, Kondo H, Bone AJ, Takasawa S, Okamoto H. Pancreatic beta-cell replication and amelioration of surgical diabetes by Reg protein. Proc Natl Acad Sci U S A 1994;91:3589-3592. ArticlePubMedPMC
- 5. Unno M, Nata K, Noguchi N, Narushima Y, Akiyama T, Ikeda T, Nakagawa K, Takasawa S, Okamoto H. Production and characterization of Reg knockout mice: reduced proliferation of pancreatic beta-cells in Reg knockout mice. Diabetes 2002;51(Suppl 3):S478-S483. PubMed
- 6. Bluth M, Mueller CM, Pierre J, Callender G, Kandil E, Viterbo D, Fu SL, Sugawara A, Okamoto H, Zenilman ME. Pancreatic regenerating protein I in chronic pancreatitis and aging: implications for new therapeutic approaches to diabetes. Pancreas 2008;37:386-395. ArticlePubMedPMC
- 7. Moriizumi S, Watanabe T, Unno M, Nakagawara K, Suzuki Y, Miyashita H, Yonekura H, Okamoto H. Isolation, structural determination and expression of a novel Reg gene, human RegI beta. Biochim Biophys Acta 1994;1217:199-202. PubMed
- 8. Rafaeloff R, Pittenger GL, Barlow SW, Qin XF, Yan B, Rosenberg L, Duguid WP, Vinik AI. Cloning and sequencing of the pancreatic islet neogenesis associated protein (INGAP) gene and its expression in islet neogenesis in hamsters. J Clin Invest 1997;99:2100-2109. ArticlePubMedPMC
- 9. National Institutes of Health. The gene expression profile in human pancreas c2006;In: Proceedings of the 66th ADA Scientific Sessions; 2006 Jun 9-13; Washington, DC: American Diabetes Association; -335-OR.
- 10. Banchuin N, Boonyasrisawat W, Pulsawat P, Vannasaeng S, Deerochanawong C, Sriussadaporn S, Ploybutr S, Pasurakul T, Yenchitsomanus PT. No abnormalities of Reg1 alpha and Reg1 beta gene associated with diabetes mellitus. Diabetes Res Clin Pract 2002;55:105-111. PubMed
- 11. Alberti KG, Zimmet PZ. Definition, diagnosis and classification of diabetes mellitus and its complications. Part 1: diagnosis and classification of diabetes mellitus provisional report of a WHO consultation. Diabet Med 1998;15:539-553. ArticlePubMed
- 12. Zhang M, Li H, Zhang Z. Clinical characteristics of early-onset type 2 diabetes and risk factors associated with its chronic complications. Zhonghua Yi Xue Za Zhi 2006;86:2547-2551. PubMed
- 13. Kim JH, Shin HD, Park BL, Cho YM, Kim SY, Lee HK, Park KS. Peroxisome proliferator-activated receptor gamma coactivator 1 alpha promoter polymorphisms are associated with early-onset type 2 diabetes mellitus in the Korean population. Diabetologia 2005;48:1323-1330. ArticlePubMedPDF
- 14. Hatunic M, Burns N, Finucane F, Mannion C, Nolan JJ. Contrasting clinical and cardiovascular risk status between early and later onset type 2 diabetes. Diab Vasc Dis Res 2005;2:73-75. ArticlePubMedPDF
- 15. Livak KJ. Allelic discrimination using fluorogenic probes and the 5' nuclease assay. Genet Anal 1999;14:143-149. ArticlePubMed
- 16. Koo BK, Cho YM, Park BL, Cheong HS, Shin HD, Jang HC, Kim SY, Lee HK, Park KS. Polymorphisms of KCNJ11 (Kir6.2 gene) are associated with type 2 diabetes and hypertension in the Korean population. Diabet Med 2007;24:178-186. ArticlePubMed
- 17. Hedrick PW. Gametic disequilibrium measures: proceed with caution. Genetics 1987;117:331-341. ArticlePubMedPMCPDF
- 18. Stephens M, Smith NJ, Donnelly P. A new statistical method for haplotype reconstruction from population data. Am J Hum Genet 2001;68:978-989. ArticlePubMedPMC
- 19. Storey JD, Tibshirani R. Statistical significance for genomewide studies. Proc Natl Acad Sci U S A 2003;100:9440-9445. ArticlePubMedPMC
- 20. Belmont JW, Gibbs RA. Genome-wide linkage disequilibrium and haplotype maps. Am J Pharmacogenomics 2004;4:253-262. ArticlePubMed
- 21. Johnson GC, Esposito L, Barratt BJ, Smith AN, Heward J, Di Genova G, Ueda H, Cordell HJ, Eaves IA, Dudbridge F, Twells RC, Payne F, Hughes W, Nutland S, Stevens H, Carr P, Tuomilehto-Wolf E, Tuomilehto J, Gough SC, Clayton DG, Todd JA. Haplotype tagging for the identification of common disease genes. Nat Genet 2001;29:233-237. ArticlePubMedPDF
- 22. Baeza NJ, Moriscot CI, Renaud WP, Okamoto H, Figarella CG, Vialettes BH. Pancreatic regenerating gene overexpression in the nonobese diabetic mouse during active diabetogenesis. Diabetes 1996;45:67-70. ArticlePubMed
- 23. Molkentin JD, Olson EN. Defining the regulatory networks for muscle development. Curr Opin Genet Dev 1996;6:445-453. ArticlePubMed
- 24. Maruyama K, Sugano S. Oligo-capping: a simple method to replace the cap structure of eukaryotic mRNAs with oligoribonucleotides. Gene 1994;138:171-174. ArticlePubMed
- 25. Mueller CM, Zhang H, Zenilman ME. Pancreatic Reg I binds MKP-1 and regulates cyclin D in pancreatic-derived cells. J Surg Res 2008;150:137-143. ArticlePubMedPMC
REFERENCES
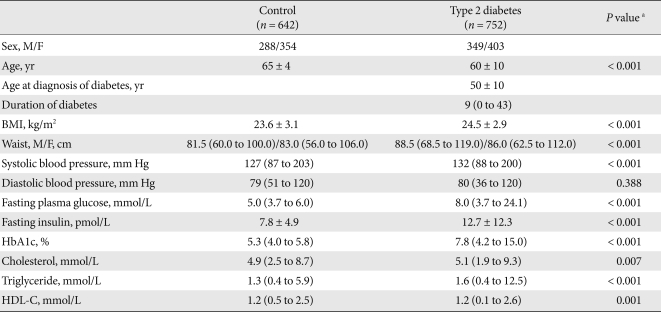
Data are given as means ± standard deviation for normally distributed variables, and otherwise as medians (range).
P values of BMI and waist circumference were adjusted for age and sex. P values of blood pressure, fasting plasma glucose, plasma insulin, HbA1c, and lipid profiles were adjusted for age, sex, and BMI.
BMI, body mass index; HDL-C, high density lipoprotein cholesterol.
aP values for differences between control group and type 2 diabetes.
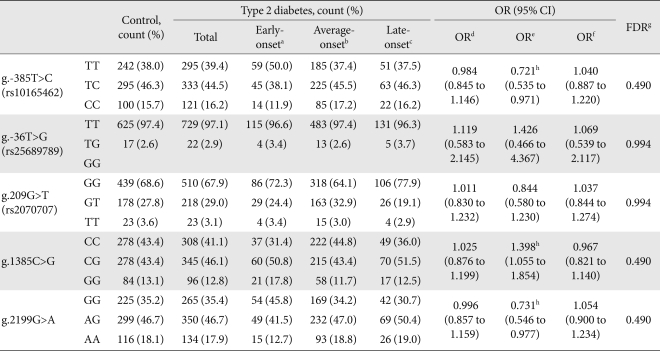
Genotype distributions are shown as numbers (%). Odds ratio (OR), 95% confidence interval (CI), and P values were obtained by logistic regression analyses. ORs are expressed per difference in number of rare alleles using an additive model.
Type 2 diabetic patients were divided into three subgroups according to age at diagnosis.
ORs are expressed per difference in number of rare alleles using an additive model after controlling for sex and body mass index (BMI).
FDR, false discovery rate.
a'Early onset' was defined as diabetic subjects with the age at diagnosis of 25 ≤ < 40, bAverage-onset included subjects with age at diagnosis of 40 ≤ < 60, cand age at diagnosis of ≥ 60 years was considered late-onset, dOR between control and all type 2 diabetes patients, eOR between normal controls and early-onset diabetes patients, fOR between normal controls and subjects with average- and late-onset diabetes, gFDR, adjusting for multiple comparisons in the multivariate binary regression analyses of additive effects of polymorphisms in early-onset diabetes compared to control subjects, hP value < 0.05.
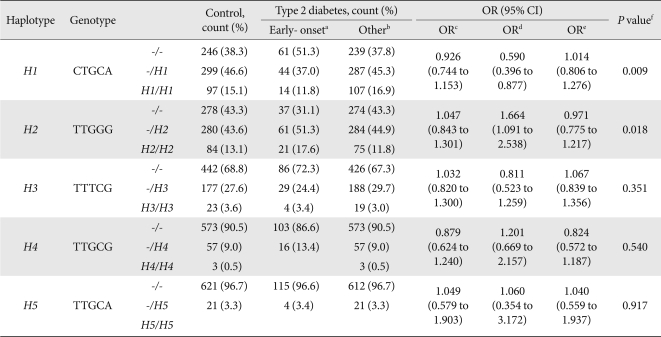
Each haplotype with a frequency of > 0.05 is shown. The genotype of each haplotype is shown according to the sequence: g.-385, g.-36, g.209, g.1385, and g.2199.
OR, odds ratio; CI, confidence interval.
a'Early onset' was defined as the diabetic subjects with the age at diagnosis of 25 ≤ < 40, b'Other' was defined as the diabetic subjects with the age at diagnosis of 40 years or more, cOR between control and all type 2 diabetes patients after controlling for sex and body mass index (BMI) using the dominant model, dOR between normal controls and early-onset diabetes patients after controlling for sex and BMI using the dominant model, eOR between normal controls and the other diabetes patients after controlling for sex and BMI using the dominant model, fP values were obtained by logistic regression analyses in the dominant model controlling for sex and BMI as covariates.
Figure & Data
References
Citations
- Glycemic Effects of Once-a-Day Rapid-Acting Insulin Analogue Addition on a Basal Insulin Analogue in Korean Subjects with Poorly Controlled Type 2 Diabetes Mellitus
Eun Yeong Choe, Yong-ho Lee, Byung-Wan Lee, Eun-Seok Kang, Bong Soo Cha, Hyun Chul Lee
Diabetes & Metabolism Journal.2012; 36(3): 230. CrossRef
 PubReader
PubReader Cite
Cite